こんにちは。大谷です。
今回は全く技術的なことに触れず、aegifという会社での働き方について紹介したいと思います。
私事で恐縮なのですが、先日娘が1歳の誕生日を迎えました。誕生日プレゼントとしておもちゃのピアノをプレゼントしましたが、今はまだ暴力的に殴りつけるor乗っかるを繰り返しています。落ち着きが無く、いたずらっ娘で、よく癇癪をおこし、暴力的で、その割には祖父母にあまりサービスせずにがっかりさせるような娘ですが、無事1歳を迎えられたことをただただ嬉しく思います。ここまで来れたのには、妻の多大なる努力と、祖父母の協力のおかげなので、感謝の気持ちを新たにしているところです。そして、その中で自分がどれだけ貢献できたのか、少し思い返すことにしてみました。
妻娘の退院後2週間は義母に寝泊まりしてもらい、その間自分は通常どおりの業務をしていました。その後1カ月は会社と交渉して自宅作業としてもらい、娘の世話と仕事を両立する生活でした。その後は結局通常どおりの業務に戻り、出社前に娘の世話をする程度しか関われていません。もちろん休日はできる限り家事・育児に関わり、妻娘が風邪をひいたときなどには有休や自宅作業などで家事や娘の世話をしています。
このように書きだしてみると、ちょっと残念ですが、自分が思い描いていたよりも育児への関与が少ないような気がしています。娘はちょうど1歳になったところなので、これから加速度的に成長・変化していき、コミュニケーションもさらに取れるようになっていくでしょう。今後は今まで以上に育児に積極的に関わり、娘や妻との時間を取れるようにしていこうと考えています。そのうち親子でピアノを連弾できたらいいななど、たくさんある夢を少しでも多く実現したいと思います。もちろんそのために会社の制度をフル活用していこうと考えていますし(制度化されてないところは最大限自分に有利なように解釈しますよ)、aegifという会社はそういう関わり方を推奨している会社だと思います。
aegifという会社はまだ小さな会社なので、整備されていない制度は必要が生じた時にその必要に応じて整備されていきます(その整備に直接関わることができます)。そして、もちろんビジネスの状況に依るところもありますが、ワークスタイルの自由を最大限尊重してくれます。このような会社でワークライフバランスを考えつつ働きたいという方がいらっしゃいましたら、是非採用に応募していただければと思います。
Saturday, December 24, 2011
Friday, December 16, 2011
AlfrescoとTesseract OCR
こんにちは!aegifの大谷です。
今回は、AlfrescoのOCR連携についてお話ししたいと思います。
私自身、営業に同行してお客様から直接お話しを伺う機会が少なくないのですが、その中でOCR連携というトピックが話題にのぼり、実際にデモを行うこともあります。弊社ではOCR連携のデモ環境を構築する際に、googleが提供するオープンソースのOCRエンジンであるTesseract OCRをよく利用しています。
以下ではAlfrescoとTesseract OCRを連携させる方法の一例を紹介しますので、参考にしていただければと思います。
1. Alfrescoをインストールし、基本的な設定を行います(こちらのスライドが参考になると思います)
2. Tesseract OCRをインストールします(こちらのサイトからダウンロードできます。インストール時にjapanese language dataにチェックを入れてください)
3. Tesseract OCRをキックするためのスクリプトを作成します(以下はWindowsでtiff形式のファイルをOCR処理する例。ファイル名はocr.batとしておきます。tmpディレクトリの作成も忘れずに!)
4. <tomcat_dir>/shared/classes/alfresco/extension/ に以下の内容のファイル ocrtiff-transform-context.xml を作成します
5. Alfrescoを起動します
6. http://<hostname>:<port>/alfresco/service/mimetypes にアクセスし、image/tiffからtext/plainへの変換が利用可能になっていることを確認します

7. 適当なフォルダを作成し、tiff画像からテキスト形式へのコンテンツ変換のルールを設定します

以上で設定は終わりです。正しく設定されていると、ルールを設定したフォルダにtiffファイルをアップロードしたタイミングでOCR処理が自動実行され、同名のテキストファイルが作成されます。

今回は、Alfrescoが用意するコンテンツ変換フレームワークと外部コマンド実行フレームワークを利用し、xmlベースの設定のみでOCRと連携するサンプルを紹介しました。ここでは詳しく説明しませんが、簡単なスクリプトを書くことで、OCRで抽出したテキストデータを元のtiffコンテンツの属性として登録するなど、さらに実用的な連携を行うことも可能です。
このように、Alfrescoはカスタマイズを容易にするために(もちろんAlfresco自体の開発を容易にするためでもありますが)様々な仕組みを用意しています。それらについては今後折を見て、具体的な例を交えつつ触れていきたいと思いますので、引き続きよろしくお願いいたします。
(2012/07/25追記:新しい記事「AlfrescoとTesseract OCR その2 (メタデータ抽出機能を使ってみた編) 」 を公開しました。こちらでは、OCRで抽出したテキストデータを元のtiffコンテンツの「説明」属性に格納するサンプルを紹介していますので、こちらも見てみてください。)
今回は、AlfrescoのOCR連携についてお話ししたいと思います。
私自身、営業に同行してお客様から直接お話しを伺う機会が少なくないのですが、その中でOCR連携というトピックが話題にのぼり、実際にデモを行うこともあります。弊社ではOCR連携のデモ環境を構築する際に、googleが提供するオープンソースのOCRエンジンであるTesseract OCRをよく利用しています。
以下ではAlfrescoとTesseract OCRを連携させる方法の一例を紹介しますので、参考にしていただければと思います。
1. Alfrescoをインストールし、基本的な設定を行います(こちらのスライドが参考になると思います)
2. Tesseract OCRをインストールします(こちらのサイトからダウンロードできます。インストール時にjapanese language dataにチェックを入れてください)
3. Tesseract OCRをキックするためのスクリプトを作成します(以下はWindowsでtiff形式のファイルをOCR処理する例。ファイル名はocr.batとしておきます。tmpディレクトリの作成も忘れずに!)
@echo off if "%1" == "" goto end if "%2" == "" goto end set tmpdir=c:\alfresco\tmp\ set ocrfilename=%tmpdir%%~n1.tif copy /B /Y %1 "%ocrfilename%" tesseract "%ocrfilename%" %~dpn2 -l jpn del "%ocrfilename%" :end
4. <tomcat_dir>/shared/classes/alfresco/extension/ に以下の内容のファイル ocrtiff-transform-context.xml を作成します
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE beans PUBLIC '-//SPRING//DTD BEAN//EN' 'http://www.springframework.org/dtd/spring-beans.dtd'>
<beans>
<bean id="transformer.worker.ocr.tiff" class="org.alfresco.repo.content.transform.RuntimeExecutableContentTransformerWorker">
<property name="mimetypeService">
<ref bean="mimetypeService" />
</property>
<property name="checkCommand">
<bean class="org.alfresco.util.exec.RuntimeExec">
<property name="commandsAndArguments">
<map>
<entry key=".*">
<list>
<value>C:/alfresco/ocr.bat</value>
</list>
</entry>
</map>
</property>
<property name="errorCodes">
<value>1</value>
</property>
</bean>
</property>
<property name="transformCommand">
<bean class="org.alfresco.util.exec.RuntimeExec">
<property name="commandsAndArguments">
<map>
<entry key=".*">
<list>
<value>C:/alfresco/ocr.bat</value>
<value>${source}</value>
<value>${target}</value>
</list>
</entry>
</map>
</property>
<property name="errorCodes">
<value>1</value>
</property>
</bean>
</property>
<property name="explicitTransformations">
<list>
<bean class="org.alfresco.repo.content.transform.ExplictTransformationDetails">
<property name="sourceMimetype"><value>image/tiff</value></property>
<property name="targetMimetype"><value>text/plain</value></property>
</bean>
</list>
</property>
</bean>
<bean id="transformer.ocr.tiff" class="org.alfresco.repo.content.transform.ProxyContentTransformer" parent="baseContentTransformer">
<property name="worker">
<ref bean="transformer.worker.ocr.tiff" />
</property>
</bean>
</beans>
5. Alfrescoを起動します
6. http://<hostname>:<port>/alfresco/service/mimetypes にアクセスし、image/tiffからtext/plainへの変換が利用可能になっていることを確認します



今回は、Alfrescoが用意するコンテンツ変換フレームワークと外部コマンド実行フレームワークを利用し、xmlベースの設定のみでOCRと連携するサンプルを紹介しました。ここでは詳しく説明しませんが、簡単なスクリプトを書くことで、OCRで抽出したテキストデータを元のtiffコンテンツの属性として登録するなど、さらに実用的な連携を行うことも可能です。
このように、Alfrescoはカスタマイズを容易にするために(もちろんAlfresco自体の開発を容易にするためでもありますが)様々な仕組みを用意しています。それらについては今後折を見て、具体的な例を交えつつ触れていきたいと思いますので、引き続きよろしくお願いいたします。
(2012/07/25追記:新しい記事「AlfrescoとTesseract OCR その2 (メタデータ抽出機能を使ってみた編) 」 を公開しました。こちらでは、OCRで抽出したテキストデータを元のtiffコンテンツの「説明」属性に格納するサンプルを紹介していますので、こちらも見てみてください。)
Monday, December 12, 2011
CMISとApache Chemistryと私
mryoshioです。
フォルダの作成
ドキュメントの作成
ドキュメントの削除
意味深なタイトルですが意味は無いです。
皆さんはApache ChemistryやCMISという言葉をご存じでしょうか。
CMISというのはContent Management Interoperability Servicesの略であり、
コンテンツ管理システム (CMS/ECM)の標準規格です。
これを使うことで、異なるベンダのバックエンドデータへのアクセスが容易になります。
たとえば、弊社で扱っているAlfrescoはCMISインターフェースをもつため、
CMIS準拠のクライアントライブラリを使うことでAlfrescoリポジトリに対する
ドキュメントの作成や削除を簡単に行えます。
次にApache Chemistryについてですが、
これはCMISに準拠したクライアントやサーバを実装するためのJavaライブラリです。
実際にこのライブラリを使い、
JavaコンソールプログラムからAlfrescoリポジトリ内を操作してみましょう。
(Alfresco Community Edition 3.4dに対し動作確認済み)
- リポジトリへの接続
SessionFactory sessionFactory = SessionFactoryImpl.newInstance(); Map parameter = new HashMap(); parameter.put(SessionParameter.USER, "admin"); parameter.put(SessionParameter.PASSWORD, "admin"); parameter.put(SessionParameter.ATOMPUB_URL, ALFRSCO_ATOMPUB_URL); parameter.put(SessionParameter.BINDING_TYPE,BindingType.ATOMPUB.value()); parameter.put(SessionParameter.REPOSITORY_ID, REPOSITORY_ID); session = sessionFactory.createSession(parameter); return session.getRootFolder();
Map props = new HashMap(); props.put(PropertyIds.OBJECT_TYPE_ID, "cmis:folder"); props.put(PropertyIds.NAME, newFolderName); Folder newFolder = target.createFolder(props); return newFolder;
Map props = new HashMap();
props.put(PropertyIds.OBJECT_TYPE_ID, "cmis:document");
props.put(PropertyIds.NAME, newDocName);
System.out.println("This is a test document: " + newDocName);
String content = "aegif Mind Share Leader Generating New Paradigms by aegif corporation.";
byte[] buf = null;
try {
buf = content.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
ByteArrayInputStream input = new ByteArrayInputStream(buf);
ContentStream contentStream = session.getObjectFactory().createContentStream(
newDocName, buf.length, "text/plain; charset=UTF-8", input);
target.createDocument(props, contentStream, VersioningState.MAJOR);
try {
CmisObject object = session.getObjectByPath(target.getPath() + delDocName);
Document delDoc = (Document) object;
delDoc.delete(true);
} catch (CmisObjectNotFoundException e) {
System.err.println("Document is not found: " + delDocName);
}
いかがだったでしょうか。
皆さんが想像されていたものと勝手が違ったかもしれません。
しかし、同じクライアントコードを使い
異なるリポジトリ (e.g. Alfresco, SharePoint)を操作できるようになれば
そのメリットは十分にあると言えるでしょう。
今回はApache Chemistryを使いましたが、
たとえばRubyベースであれば、CMISクライアント実装のActiveCMISがあります。
@mryoshio
Friday, December 2, 2011
Alfresco勉強会 #4
こんにちは!大谷です。
先日開催された第4回Alfresco勉強会に参加してきましたので、今回はその内容について書きたいと思います。
「Alfresco Java Foundation API」@mryoshio (スライド)
@mryoshioによるAlfrescoのJava APIに関する発表。Alfrescoが提供するJavaのAPIであるJava Foundation APIの解説と、Web Scriptのロジック記述をJavaで行うサンプルの紹介がありました。
「Alfresco 4.0 Solr連携を試してみた!」@_tasky (スライド)
- Web Scriptについて
- Web Scriptに関する基本的な説明と、ロジックをJavaで実装するメリットについて説明がありました。APIの豊富さとパフォーマンスの点でJavaScripよりもJavaの方に分があるとのことです。
- Java Foundation APIについて
- Java Foundation APIの基本的な説明と提供しているサービスの例、アクセス方法についての解説がありました。Spring Beanとしてインタフェースが公開されているため、DIによって簡単にAPIを利用することができます。
- [デモ] Java Foundation APIの使い方
- Web Scriptのロジック記述にJavaを用いる場合の具体的な作成・設定手順について、デモを交えながらの説明がありました。コードをgithubで公開しているそうなので是非実際に動かして確認してみてください。
続いては、@_taskyによるAlfresco Solr連携に関する発表。Alfresco 4.0で正式対応した全文検索アプリケーションSolrについて、簡単な説明と、これまでのデフォルト全文検索エンジンであるLuceneとの利用シーン比較、連携の設定方法について紹介がありました。
今回の参加者は6名でしたが、Alfrescoを使った開発を行っている方やソリューションの候補として製品選定をされている方が参加していたため、技術的なディスカッションからビジネス的な質問まで幅広く情報交換が行われました。今後も両者バランス良く(というよりも、あまりその観点にとらわれず、自由に)やっていければと思います。
次回についてはこちらで参加登録できますので、興味がある方は是非ご参加ください。
- Solrについて
- Solrに関する基本的な説明。SolrはLuceneのHTTPラッパのようなものだそうです(コアの全文検索エンジンにLuceneを使っています)
- Solr vs Lucene
- それぞれの利用シーンについての説明。スケーラビリティを求める場合はSolrを、in-transaction indexingが必要な場合はLuceneを選択した方がよいようです。
- [デモ]セットアップと動作確認
- Alfrescoが公開しているSolr連携用モジュールを使ったセットアップ方法の紹介。Alfrescoが提供するzipファイルの中に必要なファイルが全て入っているので、それらを用いて、Solrサーバ導入、Alfresco設定、TomcatのSSL設定を行うだけでセットアップが完了します。
Sunday, November 27, 2011
AnkiDroid 1.0 released!
Yesterday I released version 1.0 of AnkiDroid (flashcards app for Android).
With already 140.000 users, why is AnkiDroid only at version 1.0?
We released many 0.x versions, and now we feel the app is ready to be called 1.0!
The number of users has been multiplied by 8 in less than a year:
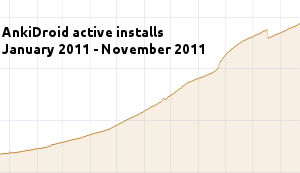
With 1.0, today is a good opportunity to describe how the AnkiDroid community of contributors works.
1) We do all we can to be friendly with all newcomers. We answer all questions and thank users for using the product.
2) We encourage everybody to participate, at every level. We introduce users to the bug tracker, and liberally give them rights to edit the Wiki, which makes them feel they are contributors rather than just users. Similarly, everyone is able to fork and edit the code, without having to ask the permission to anyone. Localization is the archetype of this spirit: Anyone can translate strings, and they are included in AnkiDroid automatically. Like on Wikipedia, consensus is the rule.
Why do we need to keep involving more and more people? Well, contributors have day jobs or exams, so their individual participation includes periods of activity alternating with periods of inactivity. See for instance this timeline of contributions, one color per contributor:
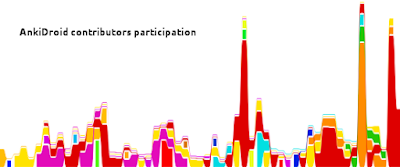
The huge majority of contributors are volunteers, but some people are also paid to contribute. Notably, the first Simplified Chinese localization has been sponsored by a Chinese company.
Geographically, developers have always been coming from very various countries: Egypt, Japan, Germany, Sweden, Spain, Brazil... Beta-testers come from virtually all over the globe, with even one in Antarctica. Thanks to this diversity, tricky issues with right-to-left languages or special characters are detected and fixed early. AnkiDroid is now available in 27 languages.
Feel free to comment if you have any question!
With already 140.000 users, why is AnkiDroid only at version 1.0?
We released many 0.x versions, and now we feel the app is ready to be called 1.0!
The number of users has been multiplied by 8 in less than a year:

1) We do all we can to be friendly with all newcomers. We answer all questions and thank users for using the product.
2) We encourage everybody to participate, at every level. We introduce users to the bug tracker, and liberally give them rights to edit the Wiki, which makes them feel they are contributors rather than just users. Similarly, everyone is able to fork and edit the code, without having to ask the permission to anyone. Localization is the archetype of this spirit: Anyone can translate strings, and they are included in AnkiDroid automatically. Like on Wikipedia, consensus is the rule.
Why do we need to keep involving more and more people? Well, contributors have day jobs or exams, so their individual participation includes periods of activity alternating with periods of inactivity. See for instance this timeline of contributions, one color per contributor:

Geographically, developers have always been coming from very various countries: Egypt, Japan, Germany, Sweden, Spain, Brazil... Beta-testers come from virtually all over the globe, with even one in Antarctica. Thanks to this diversity, tricky issues with right-to-left languages or special characters are detected and fixed early. AnkiDroid is now available in 27 languages.
Feel free to comment if you have any question!
Nicolas Raoul
Friday, November 18, 2011
Targeting China? Be prepared for additional web development costs
If you want your web application to tap into the huge Chinese market, I have a bad news for you.
Until April 2011, IE6 was still the #1 browser in China. Now it is still at 37%.
That's bad news, because IE6 is an old browser with many bugs. Making your website usable on IE6 is very complex, it will typically double your UI custom widgets development costs.
If you are not targeting China, then do like Google Apps, Facebook, Twitter and YouTube: don't invest time in making your website compatible with IE6. Actually 87% of the global top-30 websites offer a sub-optimal experience to IE6 users.
But if you are targeting China, be prepared. In particular:
Until April 2011, IE6 was still the #1 browser in China. Now it is still at 37%.
That's bad news, because IE6 is an old browser with many bugs. Making your website usable on IE6 is very complex, it will typically double your UI custom widgets development costs.
If you are not targeting China, then do like Google Apps, Facebook, Twitter and YouTube: don't invest time in making your website compatible with IE6. Actually 87% of the global top-30 websites offer a sub-optimal experience to IE6 users.
But if you are targeting China, be prepared. In particular:
- Don't use Bootstrap, Kendo UI, and most web frameworks as they don't work on IE6.
- Use Web frameworks that are committed to support IE6: 960 Grid System, HTML5 Boilerplate, GWT, among others.
Chrome recently became the second most-used browser in China, but guess what was the second-most used web browser earlier this year? Not Firefox, not Safari. It was Maxthon, from Hong Kong. It is based on Trident, just like Internet Explorer. There is also 搜狗, that can use IE and Chrome as a rendering engine. Finally, claiming 172 million active users, 360安全 is also based on Trident, and shows the same faults as IE6.
Nicolas Raoul
新しいオープンソースプロジェクト:Troois
ニコラです。
Amazon S3はファイルを書きこんだり、読み込んだりするアプリケーションにすごく便利です。とくに:
・クラウドの複数のノードで動作しているアプリケーション(この場合はファイルシステムを使えません)
・Heroku(クラウドPaaS)を使ってる場合。Herokuのファイルシステムはリードオンリーであり、Herokuのデータベースは費用が高いリソースです。
しかしAmazon S3は有料です。安価ですが、無料の選択肢があれば、下記の場合にメリットがあります:
・請求書などの複雑性を減らしたい。
・ランニングコストをゼロにしたい。例:非営利プロジェクト
・莫大な支払いのリスクを避けたい。有料サービスの場合、プログラムエラーや意図的犯行で莫大な支払いが起こる可能性があります。
Amazon S3の無料版がなかったので、作りました。Google App Engineで動作します。ソースコードをAffero General Public Licenseでオープンソースにしたので、皆さんは自由に使うことができますし、オープンにすればソースコードの変更もできます。
プロジェクトの名前は、「Troois」にしました。S3のフランス語発音「S trois」の「trois」に、Googleの「oo」を入れました。日本語の発音で「トローワ」かな…
Amazon S3と同じく、REST HTTP POSTで送ったファイルを、REST HTTP GETでダウンロードできます。
是非あなたのGoogle App Engineインスタンスで試して、フィードバックを送ってください。そして、是非是非新しい機能にご協力ください!
是非あなたのGoogle App Engineインスタンスで試して、フィードバックを送ってください。そして、是非是非新しい機能にご協力ください!
@nicolas_raoul
Monday, November 14, 2011
Mac OSXでOpenLDAPを起動
はじめまして。てらしたです。
会社のPCを新しいMacBook Proに変えてもらったので、開発環境や検証環境をつい最近整え直したんですが、あれ?こんなに簡単だったっけ?と結構意外だったものがあったので書いておきます。OpenLDAPをMac OSX 10.7(Lion)で起動するまでの手順です。で、次回とその次くらいに分けて、Apache Directory Studioで簡単なディレクトリデータベースを作って、AlfrescoでLDAP連携をする方法なんかを紹介できたらと思っています。
さて、OSXでOpenLDAPを起動する方法ですが、こちらのブログ(Starting OpenLDAP on Mac OS X Client)を参考にさせていただきました。
OSXにはもともとOpenLDAPがインストールされているので、手順は以下の3つだけです。
1. 管理者用のパスワード(rootpw)を作る。
2. slapd.confに1で作成したパスワードを設定する。
3. デーモンを起動する。
それでは、1つずつやっていきましょう。
1. 管理者用のパスワード(rootpw)を作る。
まずは管理者用のパスワードを作るためにターミナルからslappasswdコマンドを実行します。適当にパスワードを決め、2回入力するとSSHA形式(デフォルト)でエンコードされた値が生成されます。
2. slapd.confに作成したパスワードを設定する。
次に、1で作成したパスワードをslapd.confに設定します。あらかじめ用意されているslapd.conf.defaultをslapd.confとしてコピーしてから編集します。
下から7〜8行目あたりにrootpwで始まる行があるので、そこに上記で作成したパスワードをコピペし、ファイルを保存します。
3. デーモンを起動する。
これでもう準備はできたので、デーモンを起動します。
以下のようにnetstatで389番ポート(デフォルト)が使われていれば正常に起動しています。
拍子抜けするほど簡単ですが、これで終わりです。
停止したいときは、デーモンを起動したターミナルでCtrl+cでOKです。
次回は、Apache Directory Studioを使って簡単なディレクトリデータベースを作成する方法を紹介したいと思います。
会社のPCを新しいMacBook Proに変えてもらったので、開発環境や検証環境をつい最近整え直したんですが、あれ?こんなに簡単だったっけ?と結構意外だったものがあったので書いておきます。OpenLDAPをMac OSX 10.7(Lion)で起動するまでの手順です。で、次回とその次くらいに分けて、Apache Directory Studioで簡単なディレクトリデータベースを作って、AlfrescoでLDAP連携をする方法なんかを紹介できたらと思っています。
さて、OSXでOpenLDAPを起動する方法ですが、こちらのブログ(Starting OpenLDAP on Mac OS X Client)を参考にさせていただきました。
OSXにはもともとOpenLDAPがインストールされているので、手順は以下の3つだけです。
1. 管理者用のパスワード(rootpw)を作る。
2. slapd.confに1で作成したパスワードを設定する。
3. デーモンを起動する。
それでは、1つずつやっていきましょう。
1. 管理者用のパスワード(rootpw)を作る。
まずは管理者用のパスワードを作るためにターミナルからslappasswdコマンドを実行します。適当にパスワードを決め、2回入力するとSSHA形式(デフォルト)でエンコードされた値が生成されます。
$ slappasswd
New password:
Re-enter new password:
{SSHA}ppY+cX47+R0Q37G1Rkc809pS+HDvseu3
2. slapd.confに作成したパスワードを設定する。
次に、1で作成したパスワードをslapd.confに設定します。あらかじめ用意されているslapd.conf.defaultをslapd.confとしてコピーしてから編集します。
$ sudo cp /etc/openldap/slapd.conf.default /etc/openldap/slapd.conf $ sudo vim /etc/openldap/slapd.conf
下から7〜8行目あたりにrootpwで始まる行があるので、そこに上記で作成したパスワードをコピペし、ファイルを保存します。
rootpw {SSHA}ppY+cX47+R0Q37G1Rkc809pS+HDvseu3
3. デーモンを起動する。
これでもう準備はできたので、デーモンを起動します。
$ sudo /usr/libexec/slapd -d 255
以下のようにnetstatで389番ポート(デフォルト)が使われていれば正常に起動しています。
$ sudo netstat -an | grep 389 tcp4 0 0 *.389 *.* LISTEN tcp6 0 0 *.389 *.* LISTEN
拍子抜けするほど簡単ですが、これで終わりです。
停止したいときは、デーモンを起動したターミナルでCtrl+cでOKです。
次回は、Apache Directory Studioを使って簡単なディレクトリデータベースを作成する方法を紹介したいと思います。
Friday, November 11, 2011
Alfresco勉強会#3 振り返り
mryoshioです。
すでに2週経過してしまいましたが、
さる10/28に開催されたAlfresco勉強会について書きます。
Alfresco勉強会について
以前の記事にも書きましたが、
Alfrescoについての情報共有を行うものです。
少しでもAlfrescoに興味がある方なら歓迎です。
それでは第三回の内容について振り返りたいと思います。
「Alfresco 4.0を紹介してみる」@to2y (スライド)
AlfrescoやLiferayのコンサルタントである@to2yによる発表です。
バージョン4.0で強化された点に関してデモを交えつつの紹介でした。
すでに2週経過してしまいましたが、
さる10/28に開催されたAlfresco勉強会について書きます。
Alfresco勉強会について
以前の記事にも書きましたが、
Alfrescoについての情報共有を行うものです。
少しでもAlfrescoに興味がある方なら歓迎です。
それでは第三回の内容について振り返りたいと思います。
「Alfresco 4.0を紹介してみる」@to2y (スライド)
AlfrescoやLiferayのコンサルタントである@to2yによる発表です。
バージョン4.0で強化された点に関してデモを交えつつの紹介でした。
- ドラッグ&ドロップ対応
ブラウザベースのAlfresco Shareに対しドラッグ・アンド・ドロップでファイルをアップロードできるようになります。便利ですね。 - 動画、オーディオ、iWorksのプレビュー対応
これまではOfficeファイルしかプレビューできませんでした。今後はKeynoteを使っている私のような人間にも恩恵があります。助かります。 - ソーシャル機能の追加
Alfrescoが最も力を入れつつあるのがこのソーシャル機能です。Social Content Managementと言われており、コンテンツに対するレーティングや特定の人間をフォローしてフィードを受け取るといったものです。組織を介してではなく、コンテンツをベースに人と直接つながるのですね。twitterのフォローやFacebookのフレンドを考えると理解しやすいと思います.。 - Solr連携
これはまだ私自身検証ができていませんがひじょうに期待しています。というか早く試したいし触りたい。名前は出せませんが、業務で似たようなカスタマイズをしたことはあります。しかし、公式に分散環境に対応しやすくなったことは営業の仕方やシステム構成を考える際に有用です。今後の勉強会できっと誰かが話してくれるでしょう。
「Alfresco Web Script」@mryoshio (スライド)
Web Scriptの入門編として私の発表です。
余談ですが、英語版もあります。次のものから構成されています。
第三回で参加人数が初めて10名に届きました。
第四回はこちらから参加登録できます。よろしければぜひご参加ください。
(皆様の発表もお待ちしております)
Web Scriptの入門編として私の発表です。
余談ですが、英語版もあります。次のものから構成されています。
- Web Scriptとは
Web Scriptについての基本的な紹介です。 - Web Scriptの作り方
定義ファイル、ロジック、テンプレートといった構成要素の内容やサンプルの紹介です。 - Web Scriptの種類
Data Web ScriptとPresentation Web Scriptという種別と特徴を紹介しました。話を分かりやすくするために単純化してる箇所があります。大体そんなもんなんだなと割りきって読んでみてください。
第三回で参加人数が初めて10名に届きました。
第四回はこちらから参加登録できます。よろしければぜひご参加ください。
(皆様の発表もお待ちしております)
@mryoshio
Saturday, November 5, 2011
Spring Surf紹介 - インストールと最初の起動 -
とたにです。
前回はSpring Surfの成り立ちと概要について紹介しました。
今回は、いよいよインストールと初期の起動するまでを紹介したいと思います。本家にもチュートリアルがあるので、もっと詳しい手順を知りたい人はこっちも参照してみて下さい。
http://localhost:8180/ で雛形のSurfプロジェクトのWebサイトが立ち上がります。初回は必要なjarファイルをダウンロードするためにちょっと時間がかかりますので辛抱して下さい。
次回は、Surfプロジェクトのファイル構成について説明したいと思います。
前回はSpring Surfの成り立ちと概要について紹介しました。
今回は、いよいよインストールと初期の起動するまでを紹介したいと思います。本家にもチュートリアルがあるので、もっと詳しい手順を知りたい人はこっちも参照してみて下さい。
- 準備編
- インストール編
- Spring Rooのインストール
SpringSourceのサイトからSpring Roo 1.0.2をインストールします。最新は1.1.4ですが、SpringSurf 1.0.0RC2ではRoo 1.1系では一部動作しない部分もあることがフォーラムで報告されているので、ここでは1.0.2をインストールして下さい。
ダウンロードが終わったら、適当なフォルダに展開します。
spring-roo-1.0.2-RELEASE/bin/roo.sh or roo.batにパスを通しておくと
便利だと思います。
また、Maven起動時のJVMヒープを指定する環境変数を設定しておいて下さい。
MAVEN_OPTS='-Xms1024m -XX:MaxPermSize=512m'
- SpringSurfインストール
早速rooを起動します。
$ roo.sh
アドオンがインストールされrooが自動的に再起動されます。
roo> addon install --url http://www.springsurf.org/downloads/1.0.0-RC2/spring-surf-roo-addon-1.0.0-RC2-roo-addon.zip
これだけでインストールは完了です。簡単ですね。
- 最初のプロジェクト作成
作業のディレクトリを作って移動します。
$ mkdir surf-projects
いよいよrooでプロジェクトを作ります。
$ cd surf-projects
$ mkdir first-project
$ cd first-project
$ roo.sh
これで、rooの雛形プロジェクトが出来ました。
roo> project --topLevelPackage my.first.project
この時点では、SpringSurfは組込まれていません。
次のコマンドでSurfを組込みます。
roo> surf install
- 最初の起動
rooを終了し、コマンドラインから
$ mvn clean package jetty:run
と入力して下さい。
http://localhost:8180/ で雛形のSurfプロジェクトのWebサイトが立ち上がります。初回は必要なjarファイルをダウンロードするためにちょっと時間がかかりますので辛抱して下さい。
次回は、Surfプロジェクトのファイル構成について説明したいと思います。
Friday, October 28, 2011
Where to run your background jobs for free?
Until now, Google App Engine was widely seen as the perfect solution to running jobs on the cloud for free.
It is indeed powerful and convenient, offering for instance cron and task queue APIs.
I have been using GAE a lot for not-for-profit projects I am involved in, and was enchanted. The dream will end in 3 days, as this email from Google told me:
"As part of Google's long-term commitment to App Engine, we are also updating our policies, pricing and support model to reflect its status as a fully supported Google product"
In 3 days, GAE will get more expensive. Many applications will switch from the free zone to the paying zone, and they have 4 options:
- Pay
- Make the jobs faster, by writing smarter code or reducing the scope.
- Let the jobs unprocessed after quota is reached, which might be acceptable for some apps.
- Switch to an alternative service.
Under the new pricing, GAE offers 9 hours of backend instance, but most jobs will run into another limit much sooner: only 50.000 database writes are OK is the free zone. So, is it time to switch to Celadon Cedar stack to benefit from Heroku's new pricing ?
| PaaS offer | CPU time | Database operations |
| Google App Engine | 9 hours | 50.000 |
| Heroku | 720 hours | Unlimited |
The CPU time is not directly comparable, but that's still quite a difference. So, where's the catch? Well, on Heroku you either have free frontend OR free backend. If you want one worker dyno for free, you must use zero web dyno. The consequence is that implementing any kind of web interface to control your delayed_jobs is a real challenge.
@nicolas_raoul
Dominion
なくらです。
早いもので、東京に出て来てから3年経ちました。
その間にも世界はクラウドだとかソーシャルだとか目まぐるしく変化していますが、
自分はその流れに取り残されてるのじゃないという危機感が常にあります。
(ケータイも901iですしね。。。)
FaceBookやTwitterなども登録はしているのですが、ほとんど使えていません。
そもそも、公開の場所に対してメッセージを発信するなど、怖いやら、烏滸がましいやらで
今までいっさいやってこなかった、もちろんブログも書いたことがないのに
何の因果か今、ここでブログを書かされているわけです(;_;)
というわけで、情報弱者な自分が何か有益な技術ブログを書くのは無理無理なので、
最近、自分がはまっているボードゲームについて書きます。
そのゲームの名前は「ドミニオン」です。
今、割と流行っているので知っている人も多いと思います。
ざっくり説明すると、自分のデッキ(山札?)を強くしていくゲームです。
ドミニオンには基本的には3種類のカードがあって
それぞれ「勝利点」「財宝」「アクション」に分かれています。
・勝利点カードはそれ自体はゲーム中は特に効果はないのですが、ゲーム終了時にこの点数が一番多い人が勝ちになります。
・財宝カードは、勝利点やアクションカード、そして財宝カードを買うのに使います。
・アクションカードは、それ自体にいろいろな効果があって(カードを一枚引くとか)、まあ、説明は端折ります。
ゲームの流れとしては、
1.山札から五枚引いて手札とし、そこから
2.なにかアクションカードを使い、
3.手札の財宝カードを使って、何かカードを買って
4.手札を全部捨札にしてあたらしく山札から5枚引く。山札がなくなったら捨札を切って山札にする。
でターン終了です。
これを2-4人でぐるぐるとやります。
これだけ見ると単純なように見えますが、最初に使用するアクションカードをいろんな種類の中から10種類選ぶのですが、
この選び方によって、毎回ゲーム性が変わるというとても奥が深いゲームです。
10種類のカードからどんなシナジーを見つけ、どういう戦略でプレイするのかが人それぞれで、
非常に頭を使うゲームなんです。
実は、うちの会社でもドミニオンは流行中で、週に1回くらい仕事を終わった後に
オフィスで3,4人集まってドミニオンをやってたりします。
この間は、ドミニオンを使ってインターン生の面談をやってしまいました。
いや、遊びたかったんじゃなくて、
『多種多様なプロダクトが存在している現在社会において、複数のシステム間の効果的なシナジーを見抜く力を測る』
という重要な意味があったんですよ!
というわけで、最後は無理やりな感じでこのエントリも正当化して終わりたいと思います。
お粗末さまでした。
早いもので、東京に出て来てから3年経ちました。
その間にも世界はクラウドだとかソーシャルだとか目まぐるしく変化していますが、
自分はその流れに取り残されてるのじゃないという危機感が常にあります。
(ケータイも901iですしね。。。)
FaceBookやTwitterなども登録はしているのですが、ほとんど使えていません。
そもそも、公開の場所に対してメッセージを発信するなど、怖いやら、烏滸がましいやらで
今までいっさいやってこなかった、もちろんブログも書いたことがないのに
何の因果か今、ここでブログを書かされているわけです(;_;)
というわけで、情報弱者な自分が何か有益な技術ブログを書くのは無理無理なので、
最近、自分がはまっているボードゲームについて書きます。
そのゲームの名前は「ドミニオン」です。
今、割と流行っているので知っている人も多いと思います。
ざっくり説明すると、自分のデッキ(山札?)を強くしていくゲームです。
ドミニオンには基本的には3種類のカードがあって
それぞれ「勝利点」「財宝」「アクション」に分かれています。
・勝利点カードはそれ自体はゲーム中は特に効果はないのですが、ゲーム終了時にこの点数が一番多い人が勝ちになります。
・財宝カードは、勝利点やアクションカード、そして財宝カードを買うのに使います。
・アクションカードは、それ自体にいろいろな効果があって(カードを一枚引くとか)、まあ、説明は端折ります。
ゲームの流れとしては、
1.山札から五枚引いて手札とし、そこから
2.なにかアクションカードを使い、
3.手札の財宝カードを使って、何かカードを買って
4.手札を全部捨札にしてあたらしく山札から5枚引く。山札がなくなったら捨札を切って山札にする。
でターン終了です。
これを2-4人でぐるぐるとやります。
これだけ見ると単純なように見えますが、最初に使用するアクションカードをいろんな種類の中から10種類選ぶのですが、
この選び方によって、毎回ゲーム性が変わるというとても奥が深いゲームです。
10種類のカードからどんなシナジーを見つけ、どういう戦略でプレイするのかが人それぞれで、
非常に頭を使うゲームなんです。
実は、うちの会社でもドミニオンは流行中で、週に1回くらい仕事を終わった後に
オフィスで3,4人集まってドミニオンをやってたりします。
この間は、ドミニオンを使ってインターン生の面談をやってしまいました。
いや、遊びたかったんじゃなくて、
『多種多様なプロダクトが存在している現在社会において、複数のシステム間の効果的なシナジーを見抜く力を測る』
という重要な意味があったんですよ!
というわけで、最後は無理やりな感じでこのエントリも正当化して終わりたいと思います。
お粗末さまでした。
Friday, October 21, 2011
Power of community
はじめまして!aegifの大谷です。
最近、ffftpがオープンソースプロジェクトとしてその開発が継続されるというニュースがありました。自身のホームページ用にファイルをアップロードすることをはじめ、仕事でftpを使う際にもffftpを利用させていただいているので、個人的にはこのニュースをとてもうれしく思っています。
しかし、実際のところは、残念なことに開発が中断されるとその資産が塩漬けになってしまうことが多々あるようです。オリジナル開発者の都合にもよりますが、その資産をオープンソース化しコミュニティで開発を継続していくことで、単にそのツールを今後とも安定的に利用できるようになるだけでなく、以下のようなメリットも享受できるのではと考えています。
一方で、先日、英Alfresco社の会長兼CTOであるJohn NewtonがeドキュメントJapanにおいて講演を行い、オープンソースソフトウェアについて「ソフトウェアライフサイクルの全ての局面において、コミュニティの知恵を借りることでコストを削減している」と述べています。
この言葉は、単に「ただで開発を行ってくれる人がいるから助かっている」ということを言っているのではなく、「コミュニティには多様な人の知恵が詰まっており、状況に応じて最適な助力を受けられる」ということを表しているのだと思います。
- より世間のニーズに沿うような方向へと開発が進んでゆくことが期待できる
- 機能追加やバグ修正などが加速する
- 品質が向上する
「コミュニティの知恵を活用して効率良く資産価値を高めていく」
オープンソース推しの会社に身を置く者として、この当たり前のようで当たり前に行われていないことが広まっていけばいいなと思っています。
# 個人で有用なツールを開発している方はたくさんいらっしゃいますので、もし開発を中止するようなことがありましたら是非オープンソース化をお願いしたいと思います。
Friday, October 14, 2011
Spring Surfの紹介 - 概要の概要 -
とたにです。
日頃AlfrescoやLiferayなど特定のOSSプロダクトのコンサルティングをしていると、その世界では当たり前のものとして使っていても、実はあまり知られていないツールやプロダクトがあることに気付きます。
今回はそんなプロダクトの1つであるSurf Platform(以下Surf)についてご紹介したいと思います。
Surf PlatformはもともとAlfrescoのWebインタフェースのコラボレーション基盤のShareを作るために、Alfresco社の内部で開発された動作基盤で、具体的には、WebScriptと呼ばれるWebベースのインタフェースを管理し実行します。
SurfはAlfrescoリポジトリ本体やAlfresco Shareなどさまざまプロダクトに搭載されていて、このためAlfrescoリポジトリを操作するRESTインタフェースを簡単に追加することができるようになっています。
ここまでは単にSurf Platformとして紹介してきましたが、実は昨年SurfはSpringに寄贈され、Spring Surf
として独立したプロダクトとしてメンテナンスされています(リードの開発者はAlfresco社のメンバですが)。SpringではIncubatorステータスですが、実際にはEnterprise向けプロダクトのAlfrescoでは以前から組込まれて利用されているモジュールなので、機能の完備性ではIncubatorレベルはクリアしていると言えるでしょう。
今日時点でSpringSurfのプロダクトページを見ると、1.0.0が記載されていますが、ドキュメントが全てそろっていなかったり、Eclipseのupdateサイトからはモジュールが取得できなかったりと不十分な状態なので現在準備中だと思われます。現時点の実質的な最新バージョンは1.0.0RC2ですので、1.0.0の正式版が出るまではこのバージョンを使って下さい。
Spring Surfは、Springと冠しているだけあってSpring MVCなどのSpring Framework 3.0系のモジュール群の上で動作しています。そのため、Springのbeanインジェクションを使った動作拡張や他のSpringモジュルとの連携などが容易な点がメリットとして挙げられます。また、出自がAlfrescoということもあり、設定ファイルの一部をコメントアウトするだけで、バックエンドのAlfrescoと認証連携したり、AlfrescoのREST APIを簡単に呼び出したりすることもできます。
次回はSpring Surfで最初のWebサイトを起動するまでの手順をご紹介します。
Friday, October 7, 2011
LiferayのAjaxカスタムポートレット作ってみました
吉岡です。
最近liferayのカスタムポートレットを作りました。
せっかくなのでこの場を借りてご紹介します。
以下、ポイント
- 施設予約管理 (施設ポートレット + 予約ポートレット)機能
- AUI + YUI2ベースでUIを作成し、基本的にAjax動作
- 権限部分は細かくみてない (信頼の置けるグループ内でお使いください)
- ソースコード一式はここにあります
続けて上記各ポイントについて
1.
営業の先々で某グループウェアと比較されることが多く「施設管理的な機能はないの?」とよく言われるのでこれを作りました
2.
値を追加/更新/削除するだけでページ全体が切り替わるのがそもそもどうなのという思いがあったのでLiferayポートレット作成の習熟度向上を兼ねてAjax化。LiferayにはもともとAlloy UIというjsとcssをラップしたものがあります。しかし、Alloy UIで提供されている機能では目的を実現できず仕方なくAlloy UIがラップしているYUIの機能を直接呼び出すなど汚くなってしまいました
3.
権限を細かく見てないというのはたとえば他ユーザが登録したものを削除できるということ。信頼の置けるメンバでグループポータル (ページ)を作りそのなかでお使いください。信頼できない人と使うことは推奨できません。先に信頼関係を築いてください
今後似たようなものを作ろうとする方には参考にして頂ければ幸いです。
Alloy UIを使わず最初からjQueryなどで統一的に作った方がよいかもしれません。
これを使われたり改造された場合には何らかのフィードバックを頂ければ幸いです。
@mryoshio
Friday, September 30, 2011
Alfresco勉強会について
aegifでOSSコンサルティングをしている吉岡です。
今回は8月から月一度行われているAlfresco勉強会についてご紹介します。
エンドユーザ間での情報共有を目的として弊社マーケティング部門が開催しています。
Alfrescoをすでに使われている方はもちろん、
少し興味があるという方もどしどしご参加くだされば幸いです。
私も営業的な話を離れ、Community版のカスタマイズ方法などを毎回話すつもりです。
参加人数については、徐々に増えればよいかという気持ちでやっています。
これまでの内容は、
[第一回]
- Alfrescoのインストールと設定 (@mryoshio スライド)
- 設定やルールについての話 (@nicolas_raoul)
[第二回]
これまでは不本意ながらaegifの人間しか発表していないので
今後は他の方にも気軽に話していただければ嬉しいです。
内容も入門者/上級者向け、開発者/管理者向けなど
バラエティに富んだものにしていきたいと考えています。
ゆるい雰囲気で実施されるのでどうぞお気軽にご参加ください。
第三回Alfresco勉強会のお申し込みは こちら からどうぞ
@mryoshio
Sunday, September 25, 2011
ごあいさつ
はじめまして。aegif labo blogにようこそ!
aegifでオープンソースコンサルティングに携わっている戸谷(とたに)ともうします。
このブログでは開発しているプロダクトの紹介、勉強会のレポート、オープンソースに関する調査や雑感などを紹介していきます。
aegifはオープンソースECMのAlfrescoや、ポータルプラットフォームのLiferayのパートナーとして、これらのプロダクトの導入コンサルティングや技術支援などを行っています。AlfrescoもLiferayも非常にすじの良いプロダクトで、だからこそパートナーとして普及につとめているのですが、一方でどのように使えるのか、また実際にカスタマイズするにはどうしたらいいのか、こういった情報が特に日本語では不足していて、まず使ってみようと思っても一歩が踏み出せない方が多いのではないかと思います。このブログでは勉強会のレポートなどを通して、これらプロダクトについての情報を発信していく予定です。
また、社内では実プロジェクトや検証評価などで他のオープンソースプロダクトもあつかっていますので、AlfrescoやLiferay以外のプロダクトも積極的に取り上げたいと思ってます。
さらに実際のプロジェクトや技術評価にて、カスタマイズモジュールやプロダクトのプラグインなど、さまざまなモジュールを開発しています。これらについても可能なものはソースコードを公開し使い方や解説などを紹介していきます。
ぜひご期待ください。
Subscribe to:
Comments (Atom)