こんにちは!aegifの大谷です。
以前の記事からだいぶ時間が経ってしまいましたが、AlfrescoのOCR連携について、もう少し実用的な例を紹介します。今回は、Alfrescoのメタデータ抽出機能(Metadata Extraction)を利用し、OCRの出力結果文字列をコンテンツの属性に保存し、全文検索できるようにしてみたいと思います。
メタデータ抽出機能って何?
メタデータ抽出機能とは、コンテンツ実体(ファイル)の中身を解析し、コンテンツの属性(メタデータ)にコンテンツ実体から抽出したパラメータを格納する機能です。
例えば、Microsoft Officeファイルは「ドキュメントのプロパティ」として「タイトル」「作成者」「会社名」などの情報を保持していますが、AlfrescoにMicrosoft Officeファイルをアップロードすると、自動的にファイルを解析してこれらの情報を抽出し、コンテンツのしかるべき属性にセットします。
Alfrescoにはデフォルトで多数のファイル形式に対してメタデータ抽出が設定されているので、コンテンツ登録時の属性登録が自動化され、登録の手間が省けます。
今回は、カスタムのメタデータ抽出を定義し、OCR出力文字列をコンテンツの属性にセットします。
(メタデータ抽出に関する詳しい説明は
こちらを参照してください)
まずは事前準備
カスタムのメタデータ抽出を定義する前に、OCRのセットアップを行います。今回も前回と同様、Tesseract OCRを利用します。今回は、
以前の記事の手順1から3を実施しておきます。
カスタムのメタデータ抽出を実装する
では実際にカスタムのメタデータ抽出を作成していきます。実際にメタデータ抽出が行われるようにするためには、カスタムメタデータ抽出を実装し、その実装クラスをSpringビーンとしてAlfrescoに登録します。
まず、カスタムメタデータ抽出の実装を行います。メタデータ抽出用のクラスを作成するにあたっては、ベースクラスとしてAbstractMappingMetadataExtracterやTikaPoweredMetadataExtracter等が用意されていますが、今回はApache Tikaが提供するメタデータ抽出も利用するため、TikaPoweredMetadataExtracterを利用します。 拡張時のポイントは以下のとおりです。
- SUPPORTED_MIMETYPESの設定:今回はtiffのみを対象とするため、image/tiffを設定します。
- ocrCommand変数の追加:Alfrescoから外部コマンドを実行する仕組みであるRuntimeExecを利用してTesseract OCRをキックするために、RuntimeExec型の変数とsetterを定義します。インスタンスはSpringのDIによってセットされます(後述)。
- getParserメソッドのOverride:Apache Tikaが提供するTiffParserを決め打ちで返すようにします。
- extractRawメソッドのOverride:メタデータ抽出ロジックを書きます。今回はApache Tika標準のメタデータ抽出を行ったあと、OCRを実行して結果のテキストをcm:descriptionにセットします。
以下がサンプルコードになります(exceptionハンドリングとかいろいろはしょってますので適宜実装してください)。
TiffOcrMetadataExtractor.java
package jp.aegif.sample.tiffocr;
public class TiffOcrMetadataExtractor extends TikaPoweredMetadataExtracter {
protected static Log logger = LogFactory.getLog(TiffOcrMetadataExtractor.class);
private RuntimeExec ocrCommand;
public static final ArrayList<string> SUPPORTED_MIMETYPES = buildSupportedMimetypes(
new String[] {"image/tiff"},
new TiffParser()
);
public TiffOcrMetadataExtractor() {
super(SUPPORTED_MIMETYPES);
}
public void setOcrCommand(RuntimeExec ocrCommand) {
this.ocrCommand = ocrCommand;
}
@Override
protected Parser getParser() {
return new TiffParser();
}
@Override
protected Map<String, Serializable> extractRaw(ContentReader reader) throws Throwable {
// Tika標準の抽出を行う
Map<String, Serializable> rawProperties = super.extractRaw(reader);
// OCRの出力結果テキストをcm:description属性にセットする
putRawValue(KEY_DESCRIPTION, getText(reader), rawProperties);
return rawProperties;
}
private String getText(ContentReader reader) throws Throwable {
// OCRに渡す入出力ファイルを作成
File sourceFile = TempFileProvider.createTempFile("_ocr", null);
File targetFile = TempFileProvider.createTempFile("_ocr", ".txt");
reader.getContent(sourceFile);
// OCRコマンドに渡すパラメータを設定し、OCRを実行
Map<String, String> properties = new HashMap<String, String>();
properties.put("source", sourceFile.getAbsolutePath());
properties.put("target", targetFile.getAbsolutePath());
ExecutionResult result = ocrCommand.execute(properties);
if (!result.getSuccess()) {
throw new AlfrescoRuntimeException("OCR failed : " + result);
}
// 結果の読み出し
BufferedReader br = null;
try {
br = new BufferedReader(new InputStreamReader(new FileInputStream(targetFile), "utf-8"));
StringBuffer sb = new StringBuffer();
String s;
while ((s = br.readLine()) != null) {
sb.append(s);
}
return sb.toString();
} catch (Exception e) {
throw e;
} finally {
if (br != null) br.close();
sourceFile.delete();
targetFile.delete();
}
}
}
また、以下のファイルを作成し、メタデータ格納先の属性を指定します。なお、このファイルは上記クラスのクラス名と同じファイル名とし、クラスファイルと同じディレクトリに配置してパッケージングする必要があります(=> TiffOcrMetadataExtractor.javaとTiffOcrMetadataExtractor.propertiesを同じパッケージ以下に作成してください)。
TiffOcrMetadataExtractor.properties
# Namespaces
namespace.prefix.cm=http://www.alfresco.org/model/content/1.0
# Mappings
author=cm:author
title=cm:title
description=cm:description
created=cm:created
上記2ファイルが作成できたら、jarパッケージを作成し、配置します。jarの配置先は、<tomcat_dir>/webapps/alfresco/WEB-INF/lib です。
カスタムメタデータ抽出の定義を追加する
次に、先ほど作成したカスタムメタデータ抽出クラスをAlfrescoに登録するための定義ファイルを作成します。登録にはSpringの仕組みを使うので、Springビーンとしての定義を行う必要があります。ポイントは以下のとおりです。
- parentの指定:必ずbaseMetadataExtracterを指定します。
- ocrCommandプロパティの指定:Tesseract OCRをキックするためのコマンドを指定します。
以下が定義ファイルになります。ファイル名の最後が必ず"-context.xml"となるようにします。
tiff-ocr-metadata-extractor-context.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC '-//SPRING//DTD BEAN//EN' 'http://www.springframework.org/dtd/spring-beans.dtd'>
定義ファイルが作成できたら、<tomcat_dir>/shared/classes/alfresco/extension にコピーします。Alfrescoは起動時に、内部的に指定されている定義ファイルを読み込むのですが、カスタム定義を簡単に登録できるように、デフォルト
でextensionディレクトリ以下に配置された*-context.xmlを読み込むよう設定されています。
実際に使ってみる
以上で設定は全て終わり、あとはAlfrescoを起動して動作確認をするだけです。
Alfrescoを起動したら、以下の手順に従って動作確認してみましょう。
1. ブラウザで http://localhost:8080/share/ にアクセスし、ログインします
2. リポジトリもしくは適当なサイトのドキュメントライブラリにアクセスします
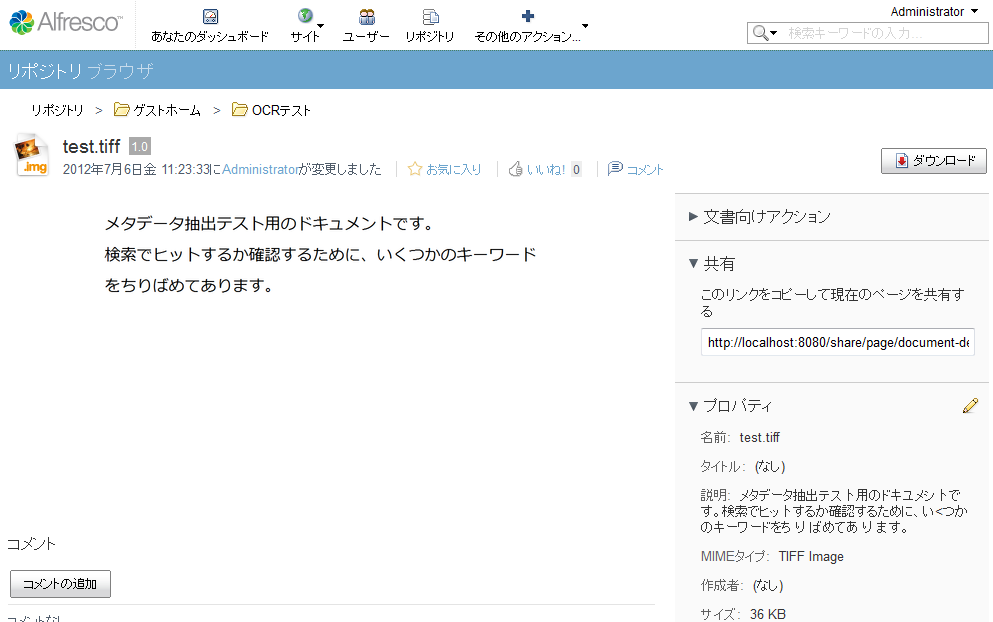
3. テスト用のtiffファイルをアップロードします
4. 以下のように、「説明」プロパティにOCR結果の文字列がセットされていることを確認します(OCR結果がイマイチなのはTesseract OCR&日本語という組み合わせだからですね…)
5. 最後に、全文検索でtiffの内容がヒットするか確認します
以上でテスト完了です!
今回は、AlfrescoとTesseract OCRを連携し、メタデータ抽出機能を使ってOCRの結果をコンテンツのプロパティに格納するサンプルを紹介しました。連携するOCRツールが変わった場合は、ocrCommandプロパティでキックするコマンドをツールにあわせて変更するだけですので、お手持ちのOCRツールがある場合はそちらとの連携も試してみるとよいかもしれません。